Publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2024
- TCSVT
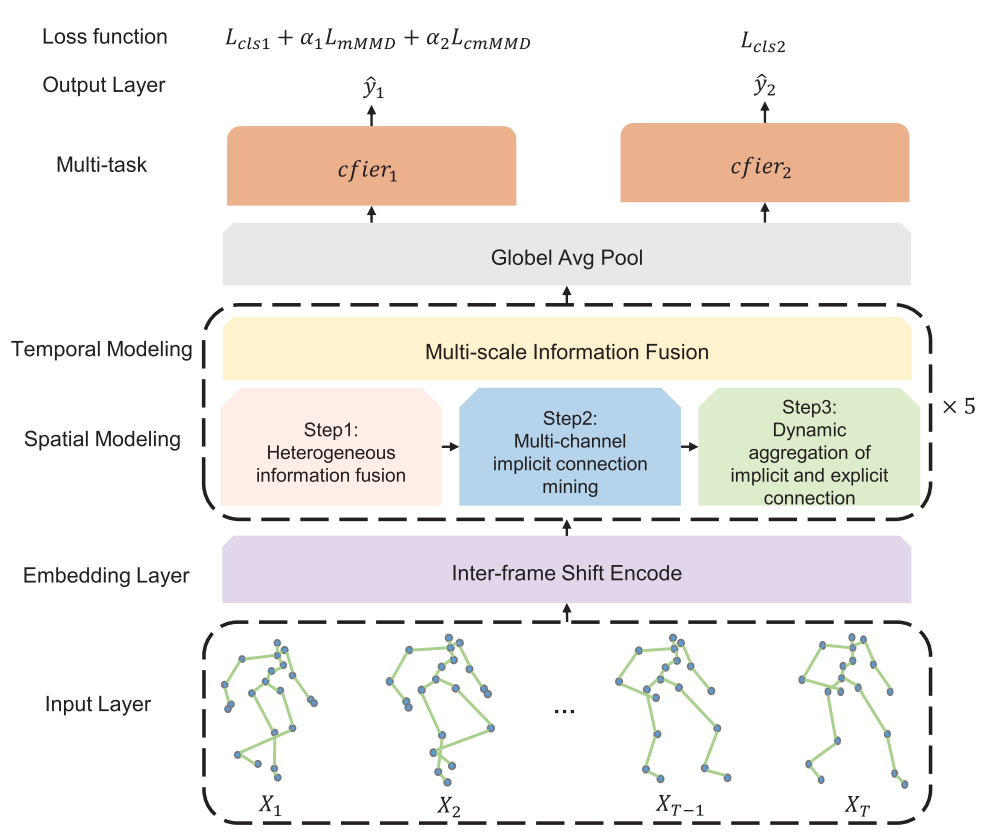 AST-GCN: Augmented Spatial Temporal Graph Convolutional Neural Network for Gait Emotion RecognitionChuang Chen, Xiao Sun*, Zhengzheng Tu, and Meng WangIEEE Transactions on Circuits and Systems for Video Technology, 2024
AST-GCN: Augmented Spatial Temporal Graph Convolutional Neural Network for Gait Emotion RecognitionChuang Chen, Xiao Sun*, Zhengzheng Tu, and Meng WangIEEE Transactions on Circuits and Systems for Video Technology, 2024Skeleton-based methods have recently achieved good performance in deep learning-based gait emotion recognition (DL-GER). However, the current methods have two drawbacks that limit the ability to learn discriminative emotional features from gait. First, these methods do not exclude the effect of the subject’s walking orientation on emotion classification. Second, they do not sufficiently learn the implicit connections between the joints during human walking. In this paper, an augmented spatial-temporal graph convolutional neural network (AST-GCN) is introduced to solve these two problems. The interframe shift encoding (ISE) module acquires interframe shifts of joints to make the network sensitive to changes in emotion-related joint movements regardless of the subject’s walking orientation. A multichannel implicit connection inference method learns more implicit connection relations related to emotions. Notably, we unify current skeleton-based methods into a common framework that validates the most powerful feature representation capability of our AST-GCN from a theoretical perspective. In addition, we extend the skeleton-based gait dataset using posture estimation software. Experiments demonstrate that our AST-GCN outperforms state-of-the-art methods on three datasets on two tasks.
@article{10354012, selected = true, author = {Chen, Chuang and Sun, Xiao and Tu, Zhengzheng and Wang, Meng}, journal = {IEEE Transactions on Circuits and Systems for Video Technology}, title = {AST-GCN: Augmented Spatial Temporal Graph Convolutional Neural Network for Gait Emotion Recognition}, year = {2024}, volume = {34}, number = {6}, pages = {4581-4595}, doi = {10.1109/TCSVT.2023.3341728}, } - arXiv
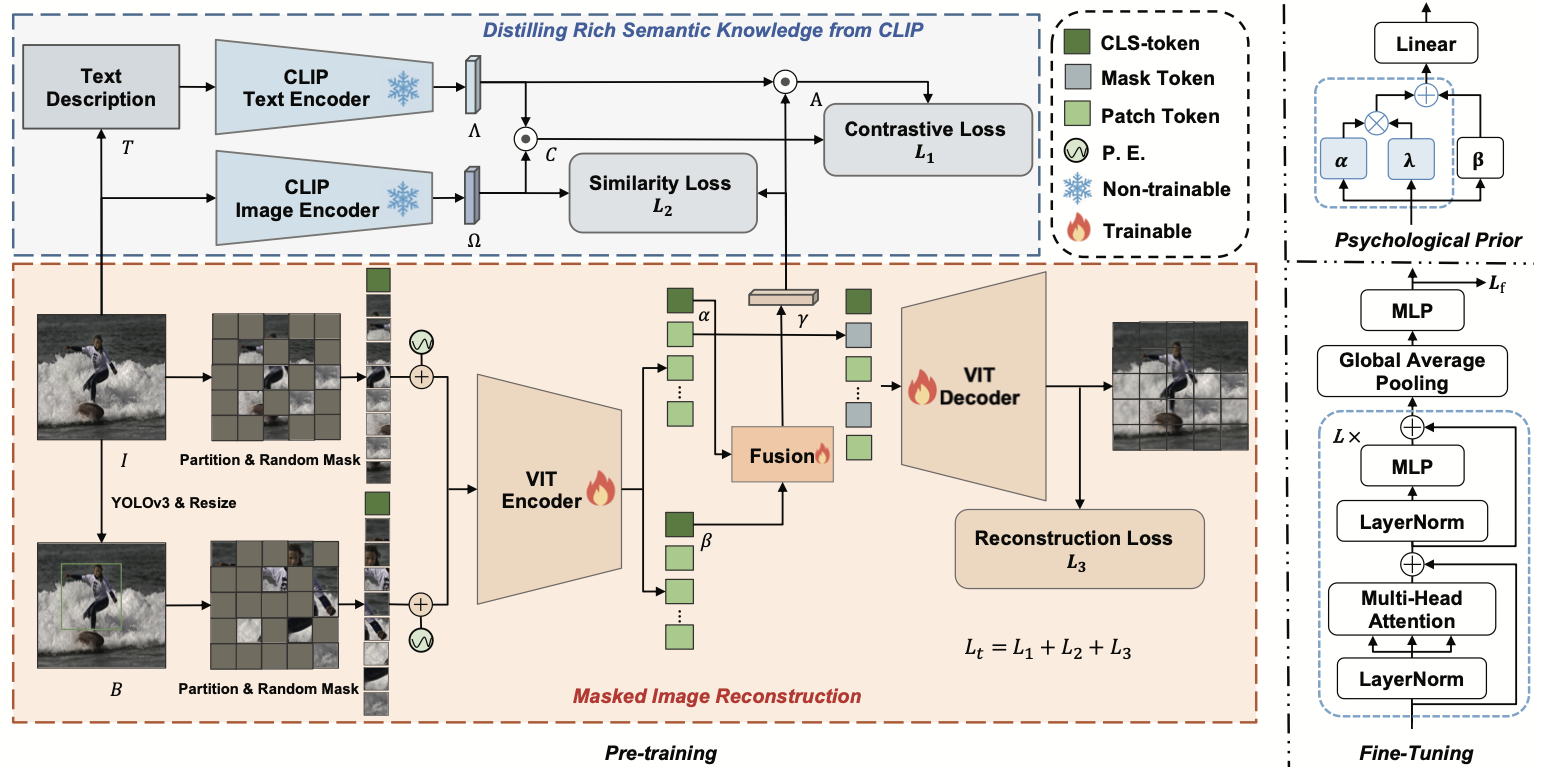 UniEmoX: Cross-modal Semantic-Guided Large-Scale Pretraining for Universal Scene Emotion PerceptionChuang Chen, Xiao Sun*, and Zhi LiuarXiv preprint (submitted to TIP), 2024
UniEmoX: Cross-modal Semantic-Guided Large-Scale Pretraining for Universal Scene Emotion PerceptionChuang Chen, Xiao Sun*, and Zhi LiuarXiv preprint (submitted to TIP), 2024Visual emotion analysis holds significant research value in both computer vision and psychology. However, existing methods for visual emotion analysis suffer from limited generalizability due to the ambiguity of emotion perception and the diversity of data scenarios. To tackle this issue, we introduce UniEmoX, a cross-modal semantic-guided large-scale pretraining framework. Inspired by psychological research emphasizing the inseparability of the emotional exploration process from the interaction between individuals and their environment, UniEmoX integrates scene-centric and person-centric low-level image spatial structural information, aiming to derive more nuanced and discriminative emotional representations. By exploiting the similarity between paired and unpaired image-text samples, UniEmoX distills rich semantic knowledge from the CLIP model to enhance emotional embedding representations more effectively. To the best of our knowledge, this is the first large-scale pretraining framework that integrates psychological theories with contemporary contrastive learning and masked image modeling techniques for emotion analysis across diverse scenarios. Additionally, we develop a visual emotional dataset titled Emo8. Emo8 samples cover a range of domains, including cartoon, natural, realistic, science fiction and advertising cover styles, covering nearly all common emotional scenes. Comprehensive experiments conducted on six benchmark datasets across two downstream tasks validate the effectiveness of UniEmoX. The source code is available at https://github.com/chincharles/u-emo.
@article{UniEmoX2024, selected = true, title = {UniEmoX: Cross-modal Semantic-Guided Large-Scale Pretraining for Universal Scene Emotion Perception}, author = {Chen, Chuang and Sun, Xiao and Liu, Zhi}, journal = {arXiv preprint (submitted to TIP)}, year = {2024}, }


2023
- ICME
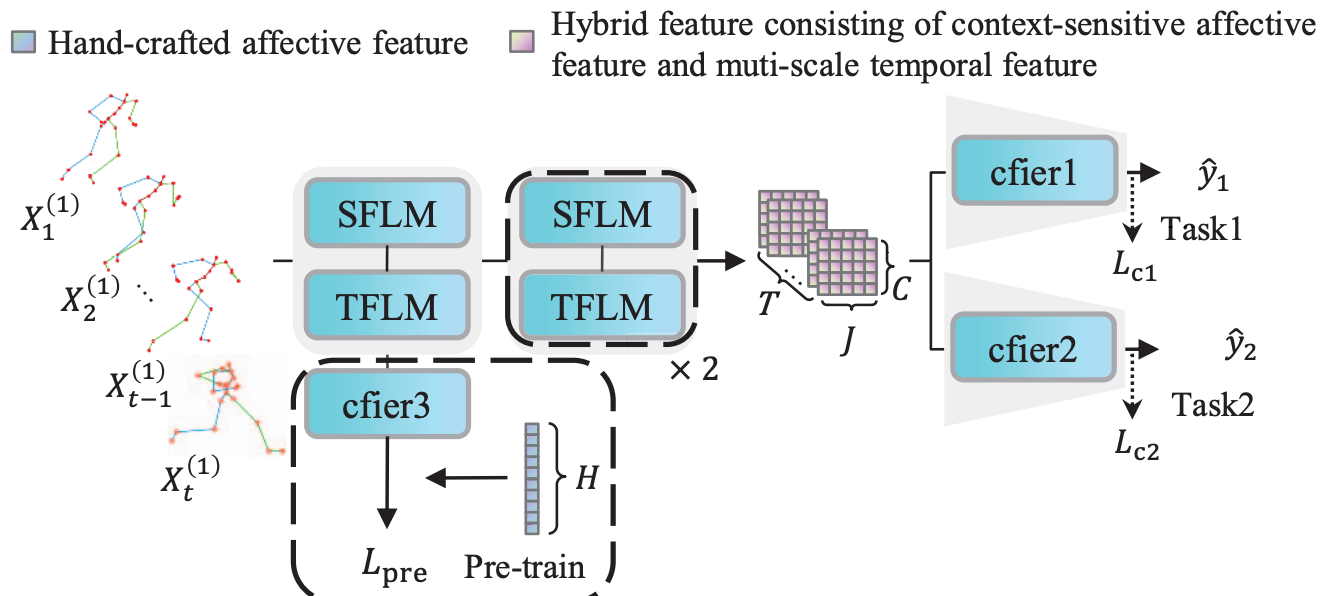 STA-GCN:Spatial Temporal Adaptive Graph Convolutional Network for Gait Emotion RecognitionChuang Chen, and Xiao Sun*In 2023 IEEE International Conference on Multimedia and Expo (ICME), 2023
STA-GCN:Spatial Temporal Adaptive Graph Convolutional Network for Gait Emotion RecognitionChuang Chen, and Xiao Sun*In 2023 IEEE International Conference on Multimedia and Expo (ICME), 2023Graph Convolutional Neural Networks (GCNs) recently have been widely used in Gait Emotion Recognition (GER). However, the existing GCNs-based GER methods have two drawbacks that limit the ability to learn discriminative feature. In spatial modeling, context-sensitive affective feature of joint is under-extracted due to the neglect of implicit connection. In temporal modeling, multi-scale temporal feature of joint motion is under-extracted or aggregated rigidly. In this paper, we propose a novel Spatial-Temporal Adaptive Graph Convolutional Network (STA-GCN) where two main modules are introduced, respectively. Spatial Feature Learning Module (SFLM) infers context-sensitive joint implicit connection and adaptively aggregates spatial feature mined from implicit and explicit connection. Temporal Feature Learning Module (TFLM) extracts and adaptively aggregates multi-scale temporal feature of joint motion. It is worth mentioning that we first pre-train the model using hand-crafted affective feature and counterpart gait. Experimental results demonstrate our STA-GCN outperforms state-of-the-art methods in two tasks.
@inproceedings{10219743, selected = true, author = {Chen, Chuang and Sun, Xiao}, booktitle = {2023 IEEE International Conference on Multimedia and Expo (ICME)}, title = {STA-GCN:Spatial Temporal Adaptive Graph Convolutional Network for Gait Emotion Recognition}, year = {2023}, pages = {1385-1390}, doi = {10.1109/ICME55011.2023.00240}, } - arXiv
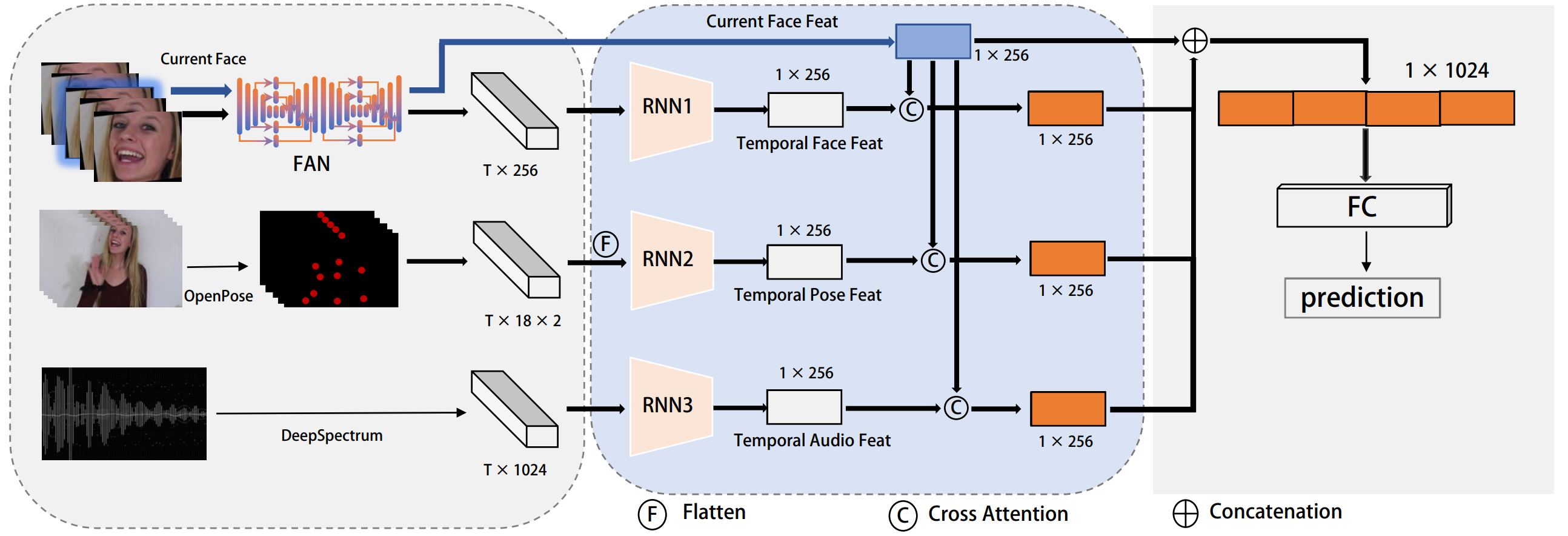 Multimodal Feature Extraction and Attention-based Fusion for Emotion Estimation in VideosTao Shu, Xinke Wang, Ruotong Wang, Chuang Chen, and 2 more authorsarXiv preprint, 2023
Multimodal Feature Extraction and Attention-based Fusion for Emotion Estimation in VideosTao Shu, Xinke Wang, Ruotong Wang, Chuang Chen, and 2 more authorsarXiv preprint, 2023The continuous improvement of human-computer interaction technology makes it possible to compute emotions. In this paper, we introduce our submission to the CVPR 2023 Competition on Affective Behavior Analysis in-the-wild (ABAW). Sentiment analysis in human-computer interaction should, as far as possible Start with multiple dimensions, fill in the single imperfect emotion channel, and finally determine the emotion tendency by fitting multiple results. Therefore, We exploited multimodal features extracted from video of different lengths from the competition dataset, including audio, pose and images. Well-informed emotion representations drive us to propose a Attention-based multimodal framework for emotion estimation. Our system achieves the performance of 0.361 on the validation dataset. The code is available at [this https URL].
@article{shu2023mutilmodalfeatureextractionattentionbased, title = {Multimodal Feature Extraction and Attention-based Fusion for Emotion Estimation in Videos}, author = {Shu, Tao and Wang, Xinke and Wang, Ruotong and Chen, Chuang and Zhang, Yixin and Sun, Xiao}, journal = {arXiv preprint}, year = {2023}, }

